Le lexème
Fonctionnement
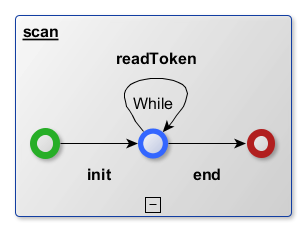
La fonction readToken retourne par défaut le token suivant, voir true si un token est passé.
Il est impératif que la règle d'analyse de base puisse identifier tous les tokens pouvant être trouvé,
sinon l'analyse risque d'être stoppé prématurément.
Pour cela il est possible d'utiliser un token nommé NOT_WHITE_SPACES détectant tout sauf un espace blanc.
Il suffit de l'ajouter en fin de règle et de surtout détecter tous les espaces blancs !